Karl Johan Alm via bitcoin-dev
2017-06-01 02:11:48 UTC
Hello,
I have spent a fair bit of time trying to nail how exactly block
filter digests[1] should be done to optimize bandwidth, space,
resource usage.
The report can be found here: http://bc-2.jp/bfd-profile.pdf
This graph shows bandwidth use of 200 wallets simulated over 5000
blocks: Loading Image...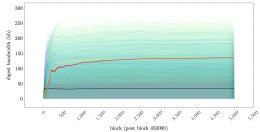 (black line is "sync once per
(black line is "sync once per
block" wallet, yellow is "sync once per 144 blocks" wallet, red is
average across all wallets).
An interesting insight made during the experiments: when allowing
digests to contain multiple blocks, the false positive rate of high
block count digests can be higher than normal, because the probability
of a false positive hit for a given entry in multiple digests,
assuming their sizes differ, is almost completely independent.
The results look rather promising to me, but I would like to hear
comments, in particular on the approach taken, if I made any faulty
assumptions, bad math mistakes, etc.
I am also curious what people consider to be acceptable costs in terms
of bandwidth use and memory (I couldn't find any stats on bandwidth
use of bloom filters). In the profiling, I restricted the field sizes
to 2^27 = 128 MB. I assumed this was appropriate as these fields are
very short lived, and in worst case, a client *could* do the scan and
decode simultaneously, without allocating up the space for the field
at all. For high block count digests (e.g. 1024 blocks), this is
sometimes overfilled. I wonder if 2^28 (256 MB) fields would be at all
acceptable or if an over-filled (high false positive rate) field is
better.
For that matter, I am not entirely sure 1024-block digests are
necessary, but they do come with an average 15 kb/block which is
pretty good.
I also wonder if the serialization approach taken is overkill or not.
It does save some space instead of simply storing "BBBAAAAA" but adds
some complexity that may not be warranted.
[1] https://lists.linuxfoundation.org/pipermail/bitcoin-dev/2016-May/012636.html
I have spent a fair bit of time trying to nail how exactly block
filter digests[1] should be done to optimize bandwidth, space,
resource usage.
The report can be found here: http://bc-2.jp/bfd-profile.pdf
This graph shows bandwidth use of 200 wallets simulated over 5000
blocks: Loading Image...
 (black line is "sync once per
(black line is "sync once perblock" wallet, yellow is "sync once per 144 blocks" wallet, red is
average across all wallets).
An interesting insight made during the experiments: when allowing
digests to contain multiple blocks, the false positive rate of high
block count digests can be higher than normal, because the probability
of a false positive hit for a given entry in multiple digests,
assuming their sizes differ, is almost completely independent.
The results look rather promising to me, but I would like to hear
comments, in particular on the approach taken, if I made any faulty
assumptions, bad math mistakes, etc.
I am also curious what people consider to be acceptable costs in terms
of bandwidth use and memory (I couldn't find any stats on bandwidth
use of bloom filters). In the profiling, I restricted the field sizes
to 2^27 = 128 MB. I assumed this was appropriate as these fields are
very short lived, and in worst case, a client *could* do the scan and
decode simultaneously, without allocating up the space for the field
at all. For high block count digests (e.g. 1024 blocks), this is
sometimes overfilled. I wonder if 2^28 (256 MB) fields would be at all
acceptable or if an over-filled (high false positive rate) field is
better.
For that matter, I am not entirely sure 1024-block digests are
necessary, but they do come with an average 15 kb/block which is
pretty good.
I also wonder if the serialization approach taken is overkill or not.
It does save some space instead of simply storing "BBBAAAAA" but adds
some complexity that may not be warranted.
[1] https://lists.linuxfoundation.org/pipermail/bitcoin-dev/2016-May/012636.html